
A note on method. This report synthesizes the public, primary-source evidence: peer-reviewed and preprint benchmarks (arXiv, OpenReview), an industry survey of 131 asset managers, and an NBER working paper. Every figure traces to the source cited beside it; the underlying dataset is open and runnable (evidence/can-ai-trade-evidence.py). Two arguments are our own and are labelled [Anthera] so you can tell our reasoning from the literature's findings. This report describes third-party studies and makes no claim about Anthera's own results.
The short version
General AI ability does not translate into trading skill. Five independent 2025–26 benchmarks say it in almost identical words.
Beating buy-and-hold is rare and regime-dependent. Where agents win, they win in calm, liquid markets — and give it back in downturns.
The returns aren't skill. Strip out market beta and style, and 9 of 10 agents had negative selection alpha.
The evidence itself is shaky. Of 19 primary studies, almost none model real costs, handle survivorship, or are reproducible.
And yet AI is real — as a co-pilot, not an autopilot. Only ~5% of asset managers let AI make autonomous trade decisions; the value today is in research, data, and risk — not autonomous alpha.
The verdict isn't "AI is fake." It's "AI is being sold as the one thing the evidence says it can't yet do."
Why we're asking
"AI that trades for you" is the most-promised, least-examined claim in markets right now. Every week brings an agent that allegedly beats the market. Almost none of those claims come with the one thing that would make them believable: an evaluation you could check.
So we did the unglamorous thing and read the evaluations — every credible LLM-trading benchmark published in 2025–26 that we could find, plus the industry's own survey data on how AI is actually used. We went in genuinely open: if agents can trade, the benchmarks should show it. This is what they show.
Can an AI agent beat buy-and-hold?
Sometimes, in the right weather, barely. StockBench — the most agent-favorable result of the set — ran 14 models over 20 large-cap stocks for four months in 2025. Most edged the buy-and-hold baseline of +0.4%. But the same paper undercuts its own headline: most models "struggle to outperform the simple buy-and-hold baseline," and critically, all of them underperformed it during the downturn and only beat it in the upturn (arXiv:2510.02209). A 4-month win in a rising market is not an edge. It's a long position with extra steps.
AI-Trader widened the lens to three markets, and the pattern sharpened: agents beat their benchmark only where the market was most liquid.
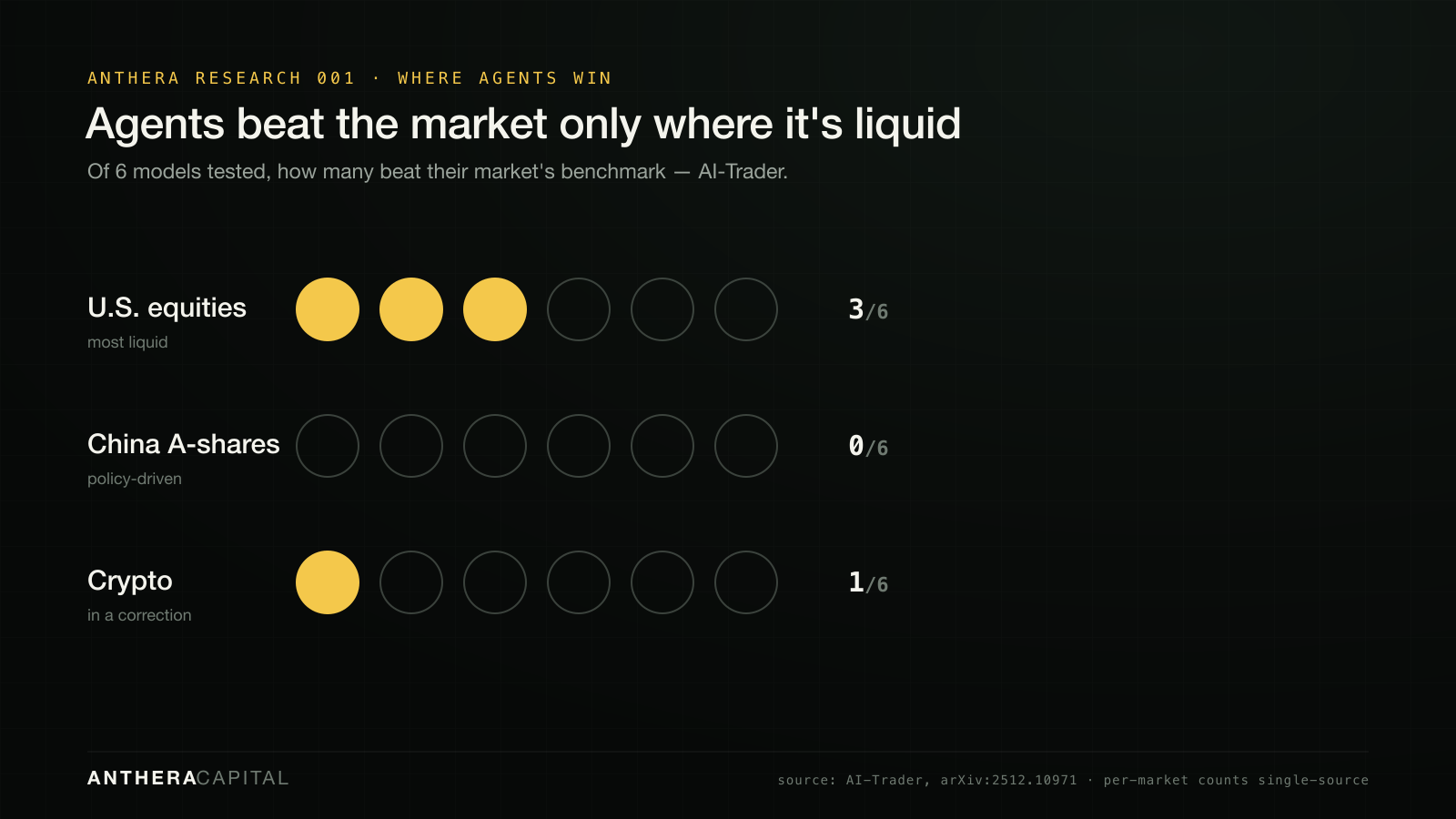
The authors' conclusion is blunt: "general intelligence does not automatically translate to effective trading capability, with most agents exhibiting poor returns and weak risk management." Two things travel across both studies: where agents add value it tends to be in risk control, not return generation; and outperformance lives in benign, liquid conditions and evaporates under stress. That is the opposite of what you want from something you'd trust with capital.
The question that matters: skill, or beta?
A return number can't tell you whether an agent was skillful or simply lucky — whether it made money by choosing well, or by being long a market that went up. The most important study in this set is the one that separates the two. KTD-Fin masked the data (anonymizing tickers and dates, so a model couldn't lean on memorized history) and ran a Barra-style attribution, splitting every agent's return into market beta, style, and genuine stock-selection alpha (arXiv:2605.28359).
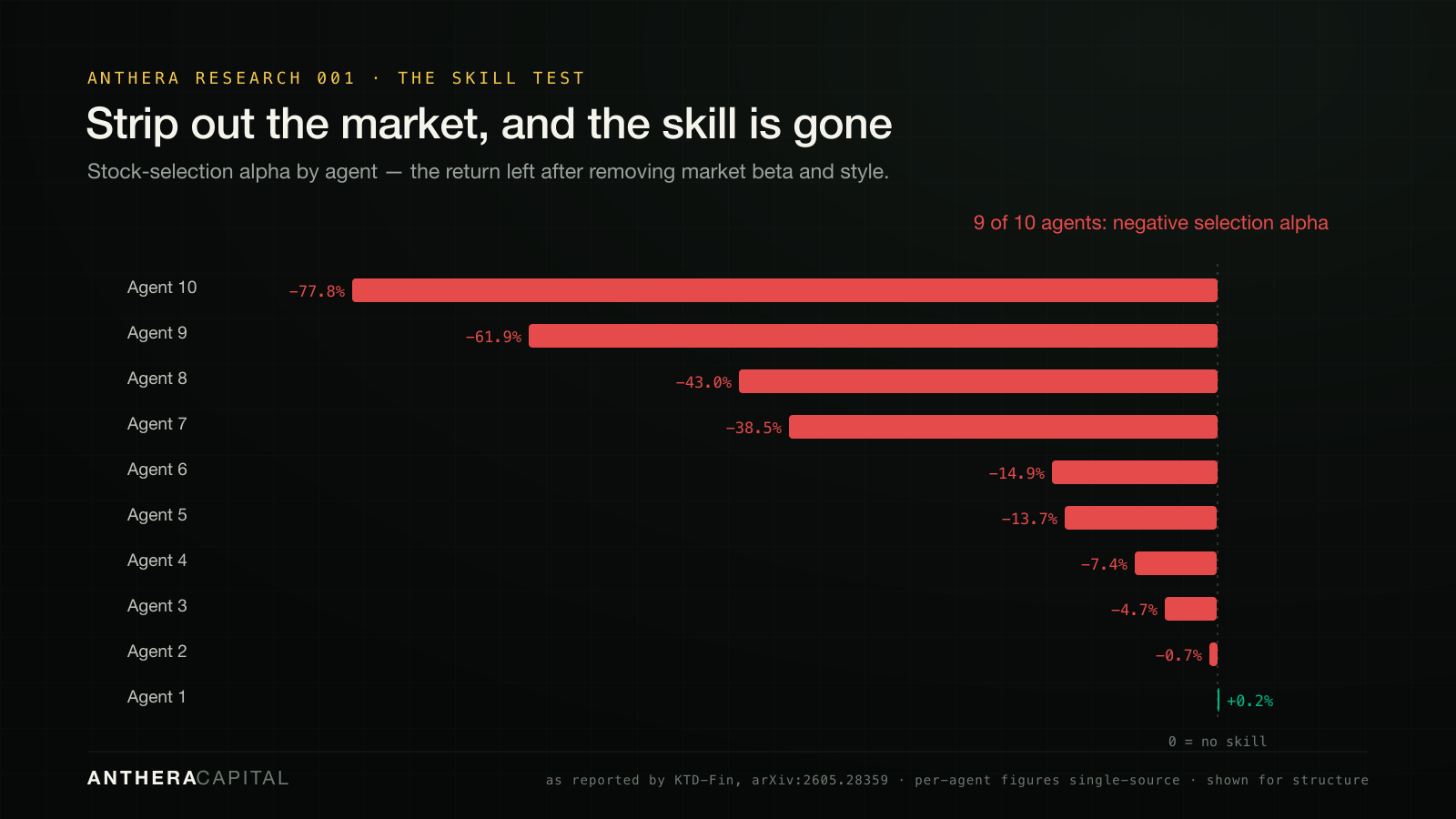
Several agents posted large headline returns — five of ten beat the index. But almost none of it was skill. As the authors report it, the selection-alpha component was negative for 9 of the 10 agents. The returns were beta and style — the market doing the work — dressed up as intelligence: "largely explained by passive market and style exposure, with limited evidence of persistent stock-selection alpha."
When the data was fully masked, the best model stopped trading on memorized brand narratives and started reasoning in raw factors — and its activity collapsed toward holding cash. The agents knew the market's history. They couldn't convert knowing into doing.
They don't adapt — and "thinking" doesn't help
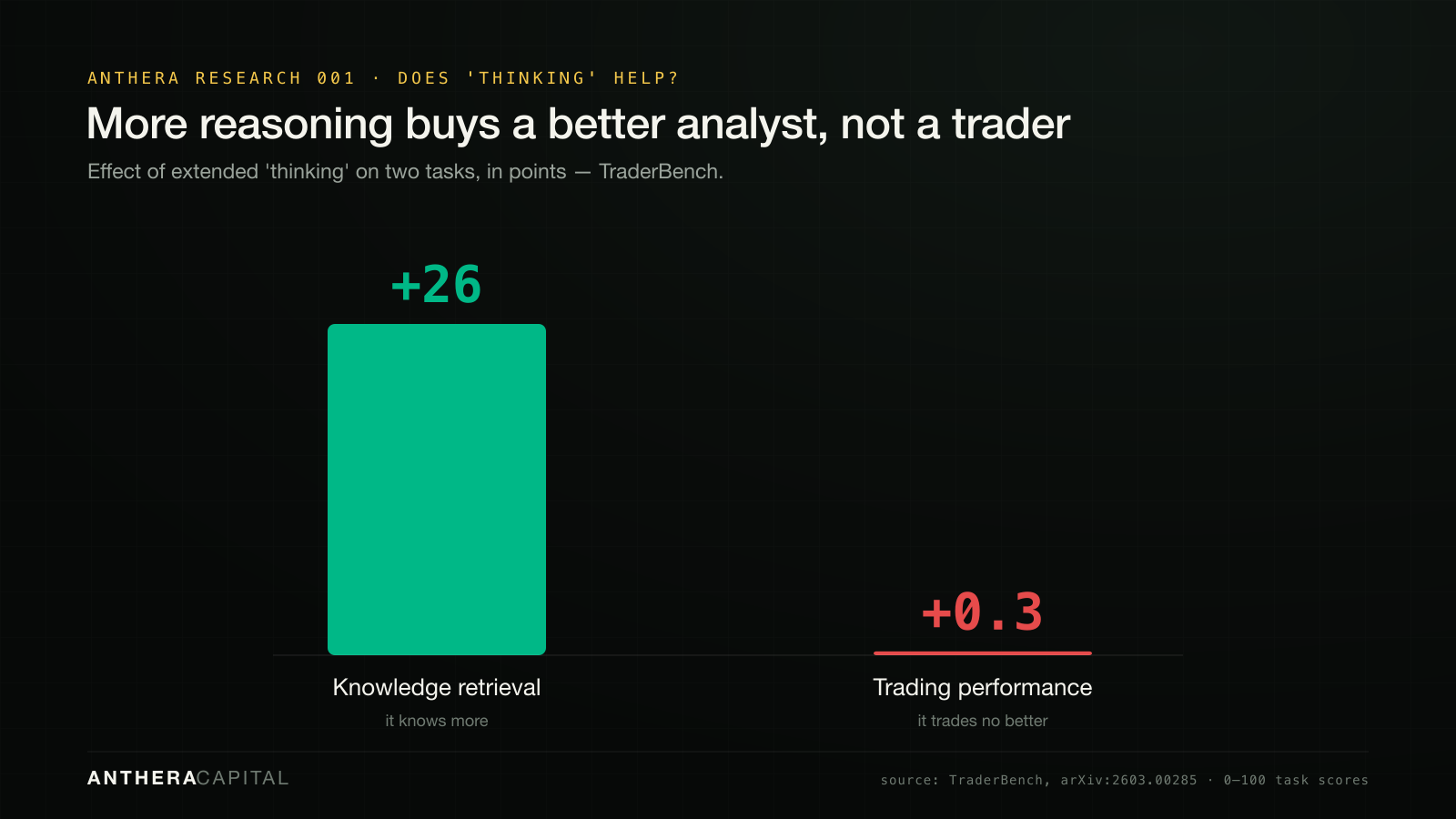
If agents were genuinely reasoning about markets, they'd behave differently when the market changed. They mostly don't. TraderBench stress-tested 13 models against progressively adversarial conditions; eight produced essentially the same score across every condition, varying by less than a point — "robustness through inaction, not genuine resilience," and a field that "lack[s] genuine market adaptation" (arXiv:2603.00285). The same study punctures the assumption that "reasoning" models should trade better.
And the upstream task is itself shaky. The Finance Agent Benchmark reports that its best-scoring model (OpenAI's o3) answered just 46.8% of expert-written financial-research questions correctly, at $3.79 a query (arXiv:2508.00828). If the research layer is wrong more often than it's right, the trading layer on top of it inherits the doubt.
The part nobody prints: the benchmarks can't be trusted either
It is not enough to ask whether the agents pass the tests. You have to ask whether the tests are any good. Mostly, they aren't yet. An evidence map of the field — 77 studies, 19 meeting the minimum bar of actually trading in a closed loop — graded the primary studies on basic standards of evidence.
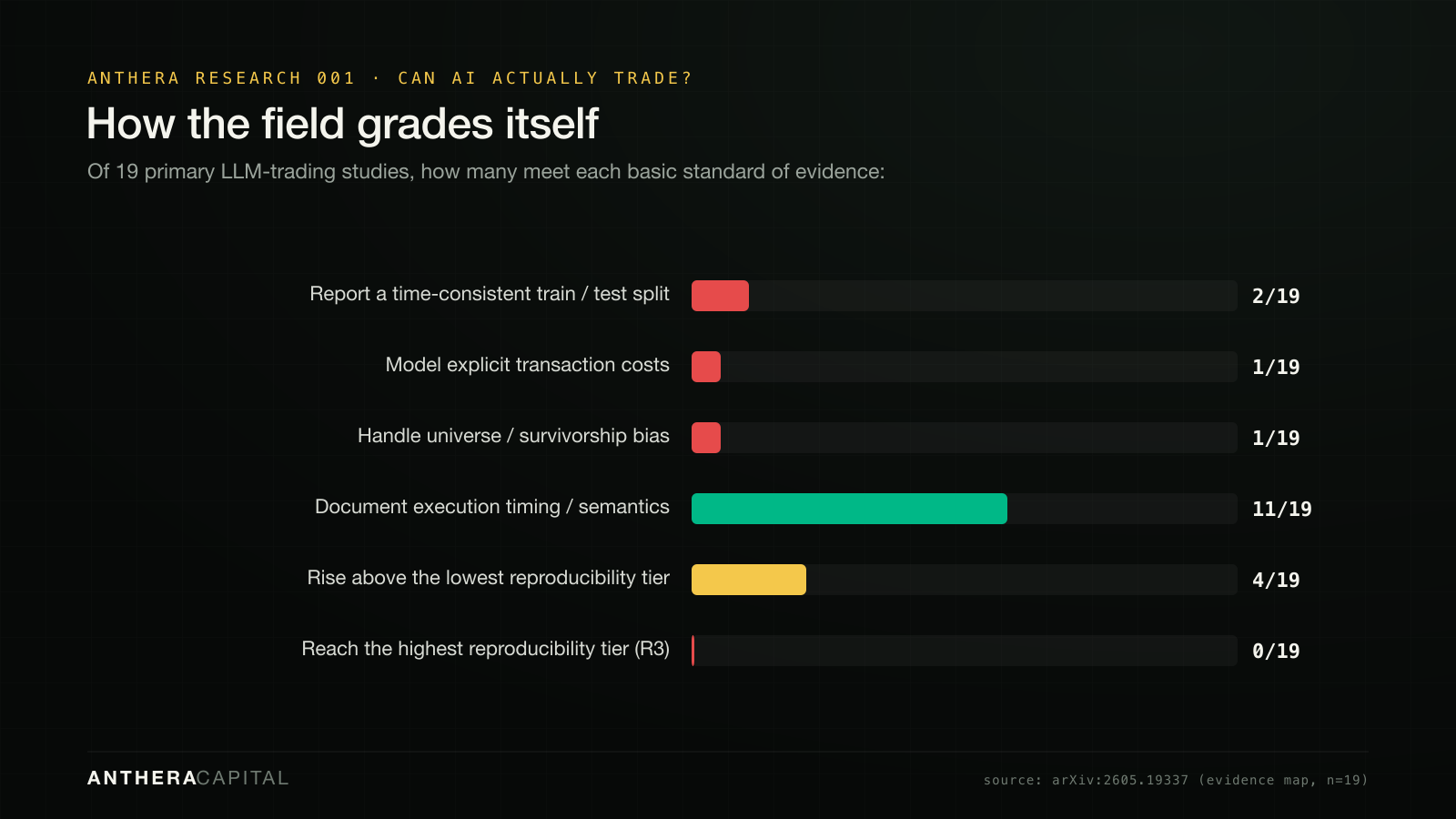
The map's own verdict is "protocol incomparability" — the studies are so methodologically inconsistent that you cannot pool them into a credible "AI beats the market" claim. The headline you keep seeing is built on sand the field itself has measured. (Like much of this literature, the map is a 2026 preprint; we lean on the direction of these counts, not the last decimal.)
Contamination is the dominant threat. If a model trained on data that overlaps the test window, it isn't predicting the future — it's remembering it. In one study, the authors report "clean" model signals produced roughly 7× the return of contamination-tainted ones (MemGuard-Alpha, arXiv:2603.26797), and that prompt-engineering and ticker-masking do not fully remove the structural leakage (arXiv:2512.23847). A benchmark is contamination-free only until it's published and crawled — after which every future model has quietly seen the answer key.
And two failure modes we'd add to the field's own list:
[Anthera] The multiple-comparisons trap. Testing fourteen models across several prompts and scaffolds and reporting the best cell is mathematically the same sin as mining a thousand backtests and publishing the highest Sharpe. With that many comparisons, a "winner" beating buy-and-hold by ~1.5 points over four months is well within what luck can produce — and none of the studies we reviewed report the dispersion that would let you rule it out. The right number was never the best agent's return; it was that return penalized for how many agents you tried.
[Anthera] Survivorship in the universe. Several benchmarks trade today's index constituents — today's survivors, chosen with hindsight — which mechanically flatters both the baseline and any long-biased agent. A classic backtest flaw, imported into AI evaluation without comment. We flag these two as our reasoning, not as cited findings, precisely because that distinction is the whole point of the report.
So what is AI for in investing?
If we stopped here, we'd be writing a hit piece — its own kind of dishonesty. AI is real, in genuine production use, and changing this industry. Just not where the marketing points.
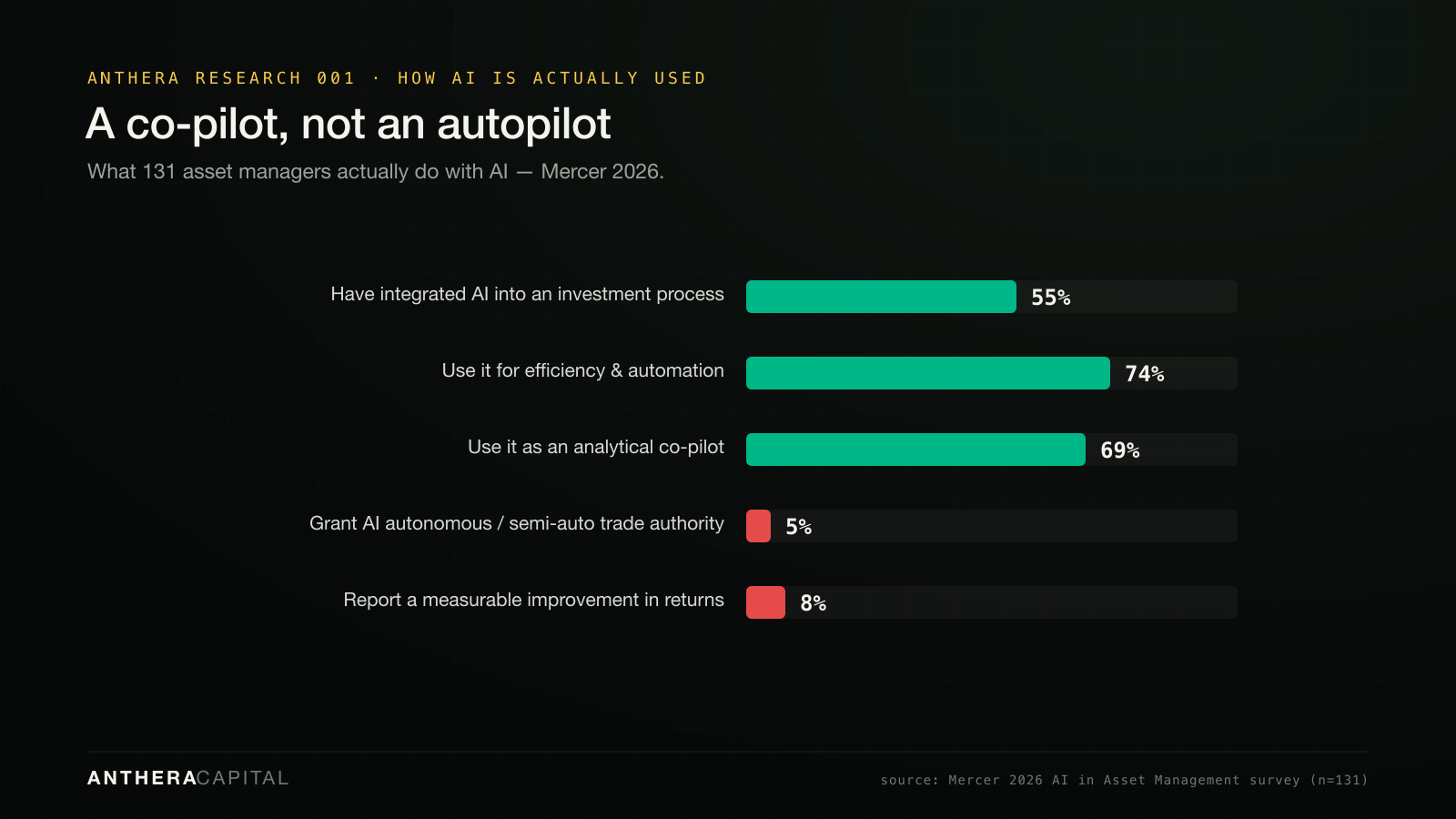
The technology is, in Mercer's research leader's words, "a partner rather than a decision-maker." Where it genuinely helps is consistent across sources: research and idea generation, processing unstructured and alternative data, generating candidate signals as inputs for humans to vet, and a large lift in analyst and coding productivity (Mercer 2026; BCG 2026; Two Sigma 2026 Outlook).
Even the most sophisticated adopters say it plainly. Two Sigma — a quant firm and aggressive AI user — writes that "AI will not magically solve the key challenges in quantitative investing: predicting the future from past data, while avoiding overfitting to backtesting results and navigating regime changes." The CFA Institute agrees: AI is "a tool for augmenting humans rather than replacing them."
The one hard piece of academic evidence cuts both ways, honestly. An NBER study found AI-driven hedge funds did outperform peers in the early years — but that outperformance decayed over time, even among early adopters (NBER w35273). Real alpha, not durable alpha. Which is exactly what you'd expect: an edge is a crowd that hasn't arrived yet.
The verdict — and why it matters
AI agents can participate in markets and occasionally beat a passive baseline — but only in benign, liquid conditions, not under stress, and the most rigorous test we have shows those returns are market beta, not skill.
No published benchmark demonstrates durable, risk-adjusted, skill-based outperformance — and the benchmarks themselves aren't yet reproducible enough to prove one if it existed. This is not an argument against using machines in markets. It is an argument against the specific fantasy being sold — the autonomous oracle that predicts prices. The evidence points somewhere more useful and more durable: AI is a powerful instrument for seeing and processing, and the edge still lives in the discipline around it — honest evaluation, real costs, risk control, and the restraint to know when a number is luck.
That happens to be the bet we've made. We don't build toward prediction; we build toward disciplined systematic method, because the evidence — not the marketing — is where we think an edge actually survives. The field can't yet grade its own homework. Until it can, treat every "AI beats the market" headline the way you'd treat a beautiful backtest. Guilty until proven innocent.
The benchmarks, at a glance
| Study | What it tested | The finding |
|---|---|---|
| StockBench 2510.02209 | 14 models · 20 DJIA stocks · 4 months | Most edged a +0.4% baseline in a calm window; all underperformed it in the downturn |
| AI-Trader 2512.10971 | 6 models · US / A-shares / crypto | Beat baseline only in liquid US (3/6); 0/6 A-shares; 1/6 crypto |
| KTD-Fin 2605.28359 | 10 models · CSI300 · leakage-controlled + attribution | Returns were beta + style; selection alpha negative for 9 of 10 |
| TraderBench 2603.00285 | 13 models · adversarial crypto + options | 8/13 froze under stress; "thinking" added +26 to knowledge, +0.3 to trading |
| Finance Agent Bench. 2508.00828 | 537 expert financial-research tasks | Best model (o3) only 46.8% accurate |
| Agentic Trading (map) 2605.19337 | Evidence map · 77 studies, 19 primary | "Protocol incomparability"; 0/19 fully reproducible |
Methods, data & sources
Reproducible evidence base: evidence/can-ai-trade-evidence.py and make-figures.py — pure-stdlib Python that prints the synthesis and regenerates every chart from the cited figures. Items marked [Anthera] are our methodological reasoning, not cited findings. Preprint figures (the arXiv-26xx series) are author-reported and not independently re-derived; confirm against the latest version before requoting.
- StockBench — arXiv:2510.02209 · AI-Trader — arXiv:2512.10971 · KTD-Fin — arXiv:2605.28359
- TraderBench — arXiv:2603.00285 · Finance Agent Benchmark — arXiv:2508.00828 · Agentic Trading map — arXiv:2605.19337
- Supporting: LiveTradeBench (2511.03628); TradeTrap (2512.02261); MemGuard-Alpha (2603.26797); Lookahead-bias test (2512.23847)
- Mercer 2026 AI in Asset Management (n=131) · BCG 2026 Global Asset Management Report · Two Sigma AI in Investment Management: 2026 Outlook · CFA Institute 2025 · NBER w35273
Anthera Capital is a systematic investment research and technology company. This report is for informational and educational purposes only — it is not investment advice, an offer or solicitation, a recommendation of any security or strategy, or a prediction of any result. It summarizes third-party research and makes no representation about Anthera's own performance. This report reflects Anthera's opinions and interpretations of third-party research as of the date of publication, is not a statement of fact about any third party, and should not be relied upon as the basis for any investment decision; third-party names and trademarks belong to their respective owners and their use implies no affiliation or endorsement. Anthera is pre-launch and not currently raising capital. Sources are third-party; we don't endorse them and may have read preprints before peer review.